Cutting the Fluff: How I Used AI to Create the Ultimate Decluttered Recipe Experience.
You can try the live tool here: https://masterchefextractor.online/

TL;DR: Recognizing the immense user frustration caused by ad-heavy, cluttered online recipe content, I developed an AI-powered web scraping agent to solve the “doom scroll”. This tool intelligently parses complex, varied webpage structures to isolate and deliver only the essential ingredients and instructions, creating a frictionless user experience. The project demonstrates how targeted AI application can solve everyday usability problems by simplifying information retrieval from messy sources.
The Problem: The Recipe “Doom Scroll”
We have all been there. It’s 6:30 PM, you’re hungry, and you just want to know how to make a chicken stir-fry. You click a promising link on Google, and instead of a recipe, you are bombarded with:
- A 2,000-word backstory about the author’s grandmother’s garden in 1995.
- Three separate pop-ups asking for your email address.
- Autoplaying video ads that follow you down the page.
- Buried somewhere at the bottom: the actual ingredients.
As a Product Manager obsessed with user experience, I saw this not just as an annoyance, but as a broken user journey. The user intent is simple (“Get recipe”), but the current solutions put massive friction between the user and their goal to maximize ad revenue.
Let’s fix this connection.
The Vision: Simplicity
My product vision was simple: Input TEXT/URL -> Output Recipe. Nothing else.
I wanted to strip away everything that wasn’t essential to the act of cooking.
However, building a traditional web scraper based on fixed HTML selectors (like Regex) fails because every recipe blog uses a different layout. One site might use <ul> tags for ingredients, another might just use bold text in paragraphs. It was too brittle.
The solution required intelligence—an agent that could “read” a webpage like a human does and understand context.
The “How”: Building the AI Scraping Agent
To achieve this, I built a workflow combining traditional web requests with an AI parsing layer. The goal was to create a generalized extractor that didn’t rely on hard-coded rules for specific domains.
Here is the technical workflow I designed and implemented:
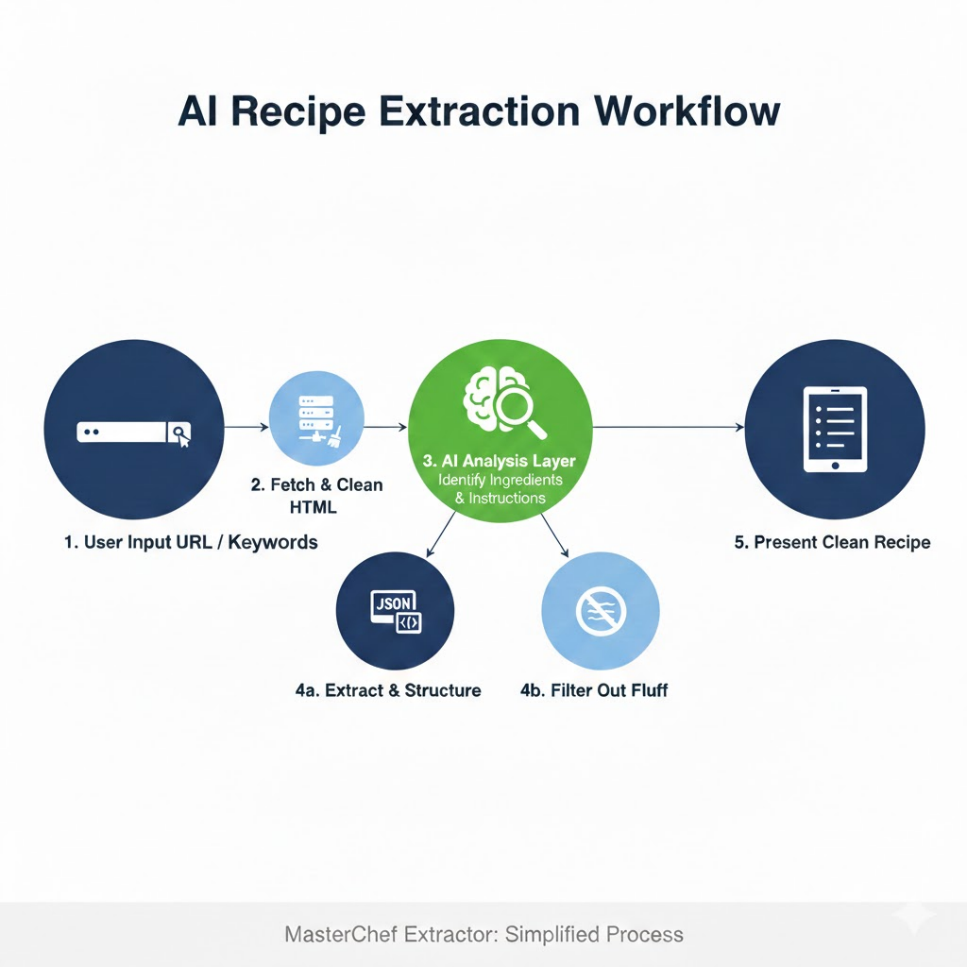
- User Input: User pastes a cluttered URL into the simple frontend interface.
- Fetch & Clean: The backend Python agent fetches the raw HTML and performs initial cleaning (removing obvious script tags, styles, and known ad-server footprints).
- AI Analysis Layer (The Brain): The cleaned DOM structure is fed into an NLP model designed to identify semantic blocks. It looks for patterns indicating lists of quantities (ingredients) and sequential imperative sentences (instructions), ignoring the “fluff” text surrounding them.
- Extraction & Structuring: The identified blocks are extracted and formatted into clean JSON.
- Presentation: The frontend renders the pure data in a minimalist, easy-to-read format.
The Result: MasterChef Extractor
The final product achieves the goal of zero-friction information retrieval. It successfully handles a wide variety of recipe site layouts, turning a frustrating 5-minute scrolling ordeal into a 5-second interaction.
It transforms the noisy internet into usable data.